
基于词表的分词算法
基于词表的方法具备如下缺陷:
对词表极为依赖,如果没有词表,则无法进行;如果词表中缺少需要的词(比如无法穷举的人名、地名),结果也不会正确
对词表极为依赖,如果没有词表,则无法进行;如果词表中缺少需要的词,结果也不会正确
如果文本中出现一定的错别字,会造成一连串影响
正向最大匹配
实现方式1
1.收集一个词表
2.对于一个待分词的字符串,从前向后寻找最长的,在此表中出现的词,在词边界做切分
3.从切分处重复步骤2,直到字符串末尾实现方式2
利用前缀字典
1.从前向后进行查找
2.如果窗口内的词是一个词前缀则继续扩大窗口
3.如果窗口内的词不是一个词前缀,则记录已发现的词,并将窗口移动到词边界
前缀字典
{
"北": 0,
"北京": 1,
"北京大": 0,
"北京大学": 1,
"北京大学生": 1,
"大": 0,
"大学": 0,
"大学生": 1
}
双向最大匹配
同时进行正向最大切分,和负向最大切分,之后比较两者结果,决定切分方式。比较标准:单字词越少越好(不在字典中的词),词数量越少越好。
JieBa分词
按照每种可能切割预料,然后统计哪种切割词频最高。
新词发现
词熵
左右熵
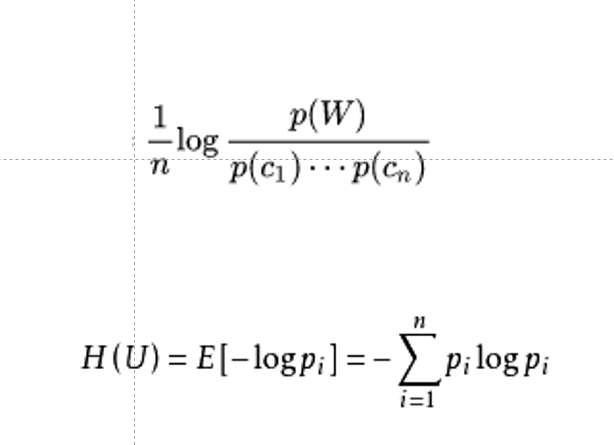
TF-IDF
算法
统计本文的关键词,在本文中出现词频很高,在其他文档中出现很少(如果太多就很泛化了,不足以表征本文)。
TF(Term Frequency,词频): 衡量词在文档中的局部重要性

IDF(Inverse Document Frequency,逆文档频率): 衡量词在全局语料库中的稀有程度


# TF 例子
文档:"猫 猫 狗 鱼"
TF(猫) = 2/4 = 0.5
TF(狗) = 1/4 = 0.25
# IDF例子
# 例子:1000篇文章中
"的"出现在 990 篇 → IDF = log(1000/990) ≈ 0.004 (极低)
"深度学习"出现在 10 篇 → IDF = log(1000/10) = 4.6 (很高)
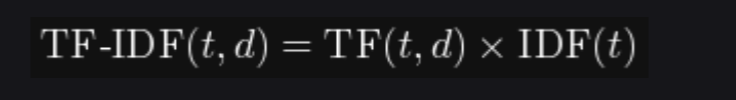
算法特点
依赖分词结果,如果分词出错,统计值的意义会大打折扣
类别数据均衡很重要
优点
可解释性好,可以清晰地看到关键词,即使预测结果出错,也很容易找到原因
计算速度快
对标注数据依赖小
缺点
受分词效果影响大;
样本不均衡会对结果有很大影响;
能力范围有限,无法完成复杂任务,如机器翻译和实体挖掘等
应用
搜索引擎
对于已有的所有网页(文本),计算每个网页中,词的TFIDF值
对于一个输入query进行分词
对于文档D,计算query中的词在文档D中的TFIDF值总和,作为query和文档的相关性得分
文本摘要
通过计算TFIDF值得到每个文本的关键词
.将包含关键词多的句子,认为是关键句
文本相似度计算
对所有文本计算tfidf后,从每个文本选取tfidf较高的前n个词,得到一个词的集合S。
对于每篇文本D,计算S中的每个词的词频,将其作为文本的向量。
通过计算向量夹角余弦值,得到向量相似度,作为文本的相似度