
流程框架
核心思想是先猜后调,属于机器学习的一种。
1. 模型随机初始化
2. 比较预期值,计算loss
3. 反向传播,更新优化器、学习率
4. 重复以上过程,直至loss收敛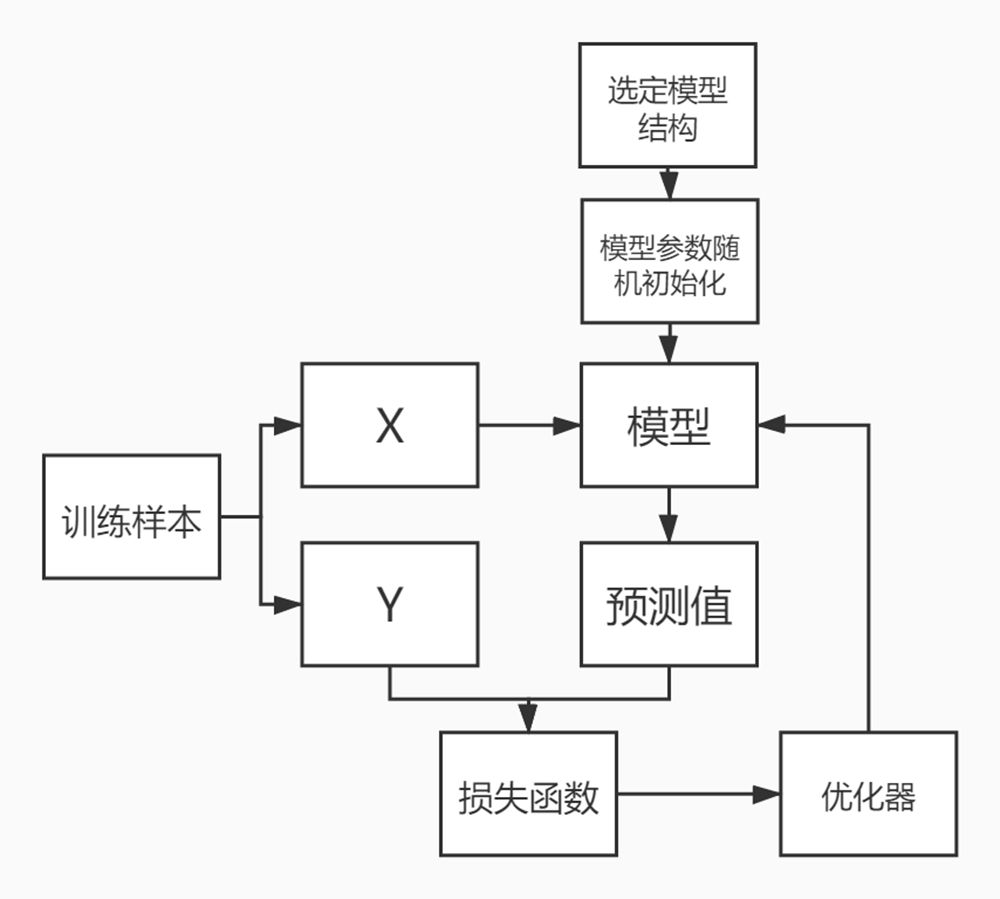
# 流程示例
import torch
import torch.nn as nn
# 1. 模型定义
model = nn.Linear(784, 10).cuda()
# 2. 损失函数 & 优化器
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
# 3. 训练循环
for epoch in range(100):
for data, target in dataloader:
data, target = data.cuda(), target.cuda()
optimizer.zero_grad() # 清空梯度
output = model(data) # 前向传播
loss = criterion(output, target) # 计算损失
loss.backward() # 反向传播
optimizer.step() # 更新参数
如何快速获得正确的模型
随机初始化
合适的loss函数
合适的参数更新策略
合适的模型架构
相关概念
优化器
根据损失函数梯度下降方向,更新模型权重参数。
Adam
特性
累加历史梯度,避免当前梯度权重过大
防止梯度爆炸、消失
随着时间步增加,梯度逐渐减小

训练
梯度爆炸和梯度消失
权重' = 权重 - 梯度 * 学习率
爆炸:梯度过大,权重参数变化较大,影响新一轮的预测值,导致新的loss反而增大,错过最小值。
消失:梯度消失,权重参数几乎无更新。
batch、epoch
epoch为完整数据集的一次训练,batch为数据集的单位切割
合适的batch可以提升训练速度,综合多个样本取较均匀的梯度。
当batch过大时,梯度更新较慢,但考虑了全样本,学习率设置稍大。
当batch过小时,梯度容易受单样本影响,出现摇摆。
损失函数
用于计算模型预测值和真实值之间的差距,当预测值和真实值越接近时,差值应该越小。
交叉熵:输出所有类别上的概率分布,最大化正确分类的概率,适用于分类任务。
均方差:衡量与目标值之间的误差,适用于回归任务。

模型结构
张量
高维向量,每个维度表示不同含义,例如`通道×高×宽` 、`头数×批次×查询长度×键长度`,在网络中传递的数据形式。
线性层
线性映射矩阵。
激活函数
非线性函数,使模型具备拟合曲线的能力。若无激活函数,多个线性映射后,还是线性关系。
激活函数的优良特性:
导数便于计算
结果在0-1之间,符合概率分布区间
常用损失函数
relu
sigmoid
tanh